스포츠 예측모델과 실제 결과 비교 방법 완전정복
페이지 정보

본문

스포츠 예측이 단순히 AI나 통계적 확률로 끝나지 않기 위해서는, 예측 모델과 실제 경기 결과 간의 차이 분석이 반드시 필요하다. 이를 통해 전략을 검증하고, ROI를 추적하며, 실패 원인을 파악하여 피드백 루프를 완성할 수 있다. 이 글은 바로 그런 목적을 달성하기 위한 스포츠 예측모델과 실제 결과 비교 방법 완전정복을 위한 20단계 자동화 설계 가이드를 제공한다.
이 가이드는 AI 기반 예측뿐 아니라 수동 분석, 커뮤니티 기반 통계 예측에도 동일하게 적용 가능하며, 정확도 분석, ROI, 리그별 성능, 시간대 성과, 실패 패턴, 자동 리포트까지 모든 요소를 통합 분석한다. Streamlit, Google Sheets, Slack과 같은 실시간 도구도 함께 연동되어 실전 적용에 최적화되어 있다.
✅ 1. 전체 워크플로우 | 시스템 개요
전체 시스템은 다음의 단계를 따라 자동화된다:
[예측 생성] → [실제 경기 결과 입력] → [정답 여부 판단] → [정확도 및 ROI 분석] → [패턴 분석] → [모델 개선 또는 전략 조정]
이 구조는 예측 결과를 단순히 맞췄는지를 넘어서, 수익성과 전략의 재사용 여부를 판단하기 위한 기반을 제공한다. 스포츠 예측모델과 실제 결과 비교 방법 완전정복의 핵심은 이 흐름을 지속 반복하며 성능을 점진적으로 개선하는 데 있다.
2. 예측 데이터 입력 구조
예측 및 결과 비교를 위한 기본 입력 데이터는 다음과 같은 형식을 따른다:
csv
복사
편집
match_id,date,home,away,predicted,pred_prob,result,home_odds,draw_odds,away_odds
1001,2025-06-01,Man City,Arsenal,Home,0.78,Home,1.55,3.50,4.20
1002,2025-06-02,Real Madrid,Atletico,Draw,0.42,Away,2.10,3.20,2.95
predicted: 예측한 결과 (Home, Draw, Away)
pred_prob: 예측 확률
result: 실제 경기 결과
이 구조는 향후 모든 분석의 기준이 되며, 모델 성능을 정밀히 비교할 수 있는 기초가 된다. 이는 스포츠 예측모델과 실제 결과 비교 방법 완전정복의 첫 번째 실천 단계다.
3. 정답 여부 계산
정답 여부는 predicted와 result의 일치 여부로 판별하며, 이를 통해 전체 정확도(Accuracy)를 산출할 수 있다.
python
복사
편집
df['correct'] = df['predicted'] == df['result']
accuracy = df['correct'].mean()
print(f"전체 적중률: {accuracy*100:.2f}%")
이 수치는 전체 전략의 1차 성과 지표이며, 정답률이 높다고 해서 반드시 수익성이 높다고 보장되지는 않는다.
4. 예측 확률 신뢰도 분석
모델이 예측에 대해 얼마나 자신감을 가졌는지를 분석하면, 확률이 높은 예측이 실제로 얼마나 정확했는지 판단할 수 있다.
python
복사
편집
plt.hist(df['pred_prob'], bins=10)
plt.title("예측 확률 분포")
예: 예측 확률 0.7 이상인 경우의 적중률이 90%라면, 해당 구간은 신뢰도 높은 전략군으로 간주할 수 있다.
5. 혼돈 행렬 및 정밀도 분석
모델의 전반적인 성능은 Precision, Recall, F1 Score 등으로 정밀하게 측정할 수 있으며, Class별로 편향된 예측 여부도 확인 가능하다.
python
복사
편집
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(df['result'], df['predicted']))
print(classification_report(df['result'], df['predicted']))
이 분석은 스포츠 예측모델과 실제 결과 비교 방법 완전정복에서 ‘모델 리밸런싱’의 기초 단계로 활용된다.
6. ROI 계산
정확도는 높더라도 수익이 없다면 무의미하다. 배당 기반 ROI 계산은 실질 수익성을 판단하는 핵심이다.
python
복사
편집
def get_odds(r):
return r['home_odds'] if r['predicted']=='Home' else r['draw_odds'] if r['predicted']=='Draw' else r['away_odds']
df['used_odds'] = df.apply(get_odds, axis=1)
df['payout'] = df.apply(lambda r: r['used_odds'] * 1000 if r['correct'] else 0, axis=1)
roi = (df['payout'].sum() - len(df)*1000)/(len(df)*1000)
print(f"ROI: {roi*100:.2f}%")
7. 배당 구간별 성능 분석
배당 구간을 나눠 각각의 성과를 확인하면, 고배당 전략 또는 저위험 정배 전략 중 어느 쪽이 더 우수했는지 분석할 수 있다.
8. 리그/종목별 정확도 분석
경기 종목 또는 리그(EPL, 라리가, KBO 등)마다 경기 특성과 배당 구조가 다르기 때문에, 예측 전략이 특정 리그에서는 잘 맞고 다른 리그에서는 부정확할 수 있다.
이를 분석하면 다음과 같은 전략적 인사이트를 얻을 수 있다:
EPL에서는 정배 중심 전략의 ROI가 높음
K리그는 무승부 발생률이 높아 별도 대응 필요
NBA는 배당 편차가 작아 높은 확률 예측이 필수
분석 예시 코드:
python
복사
편집
df['league'] = df['home'].apply(lambda x: 'EPL' if 'Man City' in x else 'La Liga')
league_grp = df.groupby('league')['correct'].agg(['count','sum'])
league_grp['accuracy'] = league_grp['sum']/league_grp['count']*100
9. 시간대별 성과 비교
경기 시간이 결과에 영향을 미칠 수 있다. 예를 들어 유럽 축구는 현지 기준 저녁에 열리지만, 한국 시간 기준 새벽이라 베팅 성향이 달라질 수 있다.
분석 포인트:
낮 경기 vs 밤 경기 성과 차이
요일별 성과 비교 (주말 경기의 혼전성 등)
특정 시간대에 높은 ROI 기록 전략 식별
라벨링 예시:
python
복사
편집
df['time_of_day'] = df['date'].apply(lambda d: 'day' if int(d[-2:]) < 18 else 'night')
이 정보를 바탕으로 시간대에 따라 전략을 분리하거나, 고위험 구간을 차단하는 설정이 가능하다.
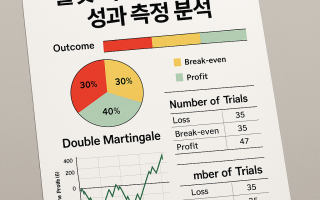
10. 누적 수익 시각화
단순 ROI 수치는 전체 수익 흐름을 설명하지 못한다. 누적 수익 그래프를 통해 예측 전략의 장기 안정성을 시각적으로 평가할 수 있다.
수익이 꾸준히 상승 → 전략 신뢰도 높음
급등락 반복 → 변동성 관리 필요
초기 손실 → 전략 초기 학습 부진 가능성
시각화 코드 예시:
python
복사
편집
df['cumulative_profit'] = df['payout'].cumsum() - 1000 * (df.index + 1)
df.plot(x='date', y='cumulative_profit', title='누적 수익 추이')
이는 투자 판단 및 전략 유지 여부를 결정하는 중요한 지표가 된다.
11. 예측 강도(p) vs 실제 정확도 비교
AI 예측 모델은 각 예측에 대해 ‘확신도(probability)’를 함께 제공한다. 이 예측 강도에 따라 실제 적중률이 일치하는지를 분석하면, 모델의 신뢰도 검증이 가능하다.
예시 구간 분류:
p > 0.9 → 확신 예측 → 실제 적중률이 높아야 정상
0.6 < p ≤ 0.7 → 중간 확신 → 전략 재학습 대상
p < 0.5 → 낮은 신뢰 예측 → 리스크 분리 또는 패스 처리
이러한 분석을 통해 베팅 필터 조건을 자동으로 구성할 수 있다.
12. 실패 패턴 분석
오답만 모아서 어떤 유형의 예측이 자주 틀렸는지를 분석하는 단계다. 예측 전략의 치명적인 약점을 조기에 발견하고 수정할 수 있다.
실전 인사이트 예:
Draw 예측은 전체 중 10%지만 실패의 40%를 차지함
고배당 예측은 대부분 실패 → 전략에서 제외 고려
특정 팀(예: Man Utd)의 예측 실패율이 높음 → 팀 기반 패널티 적용
코드 예시:
python
복사
편집
fails = df[~df['correct']]
print(fails.groupby('predicted').size())
이 결과는 다음 재학습 시 중요한 학습 데이터로 사용되며, 전략 수정의 핵심 근거가 된다.
13. Streamlit 자동 리포트 구성
Streamlit으로 작성된 리포트는 실시간으로 성과를 시각화하며, 내부 공유 또는 서비스용 대시보드로 활용 가능하다.
14. 피드백 루프 및 전략 재학습
예측 → 실제 결과 → 오답 분석 → 전략 조정 → 재학습 → 개선된 예측 생성
이 루프는 단순 분석이 아닌, 전략 최적화의 중심 구조다. 스포츠 예측모델과 실제 결과 비교 방법 완전정복을 반복 가능하게 만드는 본질적 설계다.
15~17단계 요약
Google Sheets 자동 연동: 예측, 결과, ROI, 정확도 등 통합 관리
자동 리포트 텍스트 생성: 자연어로 리포트 요약 작성
이메일/Slack 알림: 정기 리포트 자동 발송
이 기능은 시스템 운영자의 시간과 리소스를 절감하면서도 실시간 대응을 가능하게 해준다.
18. 모델 재학습 루틴
모델은 실시간 피드백을 바탕으로 지속적으로 개선되어야 한다. 오답 데이터를 강화 학습에 반영하고, 특정 클래스(예: Draw)에 대한 학습 비중을 조절한다.
19. 예측 출처별 성능 비교
수동 분석 vs AI vs 통계 기반 등 예측 출처별로 성능을 구분하면, 신뢰도 높은 출처 또는 전략을 선별해 전략 포트폴리오에 반영할 수 있다.
20. 전략 조정 및 개선 제안
분석을 통해 아래와 같은 전략 제안이 자동 생성될 수 있다:
확신도 높은 예측은 유지
Draw 예측 성능 낮을 경우, 별도 모델 분리
고배당 예측이 반복 실패 → 배당 상한선 조정
이처럼 전략 조정은 단순 수치 비교가 아니라, 성과 기반 전략 리빌딩을 유도한다.
✅ 최종 요약
스포츠 예측모델과 실제 결과 비교 방법 완전정복은 단순한 예측의 정확도 측정이 아닌, 전략의 실효성과 수익성까지 검증할 수 있는 20단계 피드백 루프를 제공한다.
예측-검증-재학습-전략 조정의 자동화 구조는 장기적인 전략 운영의 핵심이며, AI 모델뿐만 아니라 수동 분석에도 동일한 구조를 적용할 수 있다는 점에서 높은 실용성과 유연성을 자랑한다.
자주 묻는 질문 (FAQs)
Q1. 스포츠 예측 모델은 어떤 방식으로 작동하나요?
A1. 예측 모델은 과거 경기 데이터를 기반으로 AI, 통계, 수동 규칙 등의 방식으로 다음 경기의 결과를 예측합니다. 이 예측값은 확률(p)로 표현되며, 예측 강도 분석과 실제 결과 비교를 통해 성능을 검증합니다.
Q2. 예측 정확도가 높으면 반드시 수익이 나나요?
A2. 그렇지 않습니다. 예측 정확도(Accuracy)가 높아도, 선택한 배당 구간이나 베팅 전략에 따라 수익률(ROI)은 다르게 나타납니다. 예를 들어 정배(낮은 배당)의 경우 정확도는 높지만 ROI가 낮을 수 있습니다.
Q3. 수동 분석이나 커뮤니티 예측도 자동 분석이 가능한가요?
A3. 네. 예측 결과와 실제 결과를 같은 포맷(CSV 등)으로 정리하면 AI 예측뿐만 아니라 수동 분석, 커뮤니티 의견도 동일한 분석·리포트·ROI 비교가 가능합니다.
Q4. 예측 실패 시 전략 개선은 자동으로 되나요?
A4. 가능합니다. 오답 데이터를 수집하고, 일정한 규칙 또는 머신러닝 기반 피드백 루프를 통해 재학습하거나 전략 조정을 트리거로 설정할 수 있습니다. 예: 무승부 실패율이 높다면 별도 모델 적용을 제안할 수 있습니다.
Q5. Google Sheets, Streamlit, Slack 연동은 꼭 필요한가요?
A5. 필수는 아니지만, 자동화 효율성과 실시간 공유 기능을 극대화할 수 있습니다. 특히 비개발자 팀원과 협업할 때 Google Sheets는 매우 유용하며, Slack은 실시간 전략 알림에 효과적입니다.
Q6. ROI 계산 방식은 어떻게 되나요?
A6. 기본적으로 1회 베팅 1000원 기준으로, 수익률은 (총 수익 - 총 베팅금) / 총 베팅금 * 100%으로 계산됩니다. 예측이 맞았을 경우 해당 배당에 따라 수익이 누적됩니다.
Q7. 모델을 재학습하려면 어떤 데이터가 필요한가요?
A7. 예측값, 확률(p), 실제 결과, 배당, 리그 정보 등이 필요하며, 특히 오답 데이터를 포함해 어떤 조건에서 실패했는지를 포함해야 효과적인 재학습이 가능합니다.
Q8. 실패 패턴은 어떻게 분석하나요?
A8. 예측 실패 데이터를 필터링한 뒤, 예측된 방향, 배당 구간, 리그, 시간대 등 조건별로 분류해 실패가 집중된 영역을 식별합니다. 이를 통해 전략 리밸런싱 또는 리스크 회피 전략을 수립합니다.
#스포츠예측 #예측정확도 #ROI분석 #전략피드백 #피드백루프 #자동화리포트 #배당분석 #Streamlit리포트 #모델재학습 #예측전략분석
이 가이드는 AI 기반 예측뿐 아니라 수동 분석, 커뮤니티 기반 통계 예측에도 동일하게 적용 가능하며, 정확도 분석, ROI, 리그별 성능, 시간대 성과, 실패 패턴, 자동 리포트까지 모든 요소를 통합 분석한다. Streamlit, Google Sheets, Slack과 같은 실시간 도구도 함께 연동되어 실전 적용에 최적화되어 있다.
✅ 1. 전체 워크플로우 | 시스템 개요
전체 시스템은 다음의 단계를 따라 자동화된다:
[예측 생성] → [실제 경기 결과 입력] → [정답 여부 판단] → [정확도 및 ROI 분석] → [패턴 분석] → [모델 개선 또는 전략 조정]
이 구조는 예측 결과를 단순히 맞췄는지를 넘어서, 수익성과 전략의 재사용 여부를 판단하기 위한 기반을 제공한다. 스포츠 예측모델과 실제 결과 비교 방법 완전정복의 핵심은 이 흐름을 지속 반복하며 성능을 점진적으로 개선하는 데 있다.
2. 예측 데이터 입력 구조
예측 및 결과 비교를 위한 기본 입력 데이터는 다음과 같은 형식을 따른다:
csv
복사
편집
match_id,date,home,away,predicted,pred_prob,result,home_odds,draw_odds,away_odds
1001,2025-06-01,Man City,Arsenal,Home,0.78,Home,1.55,3.50,4.20
1002,2025-06-02,Real Madrid,Atletico,Draw,0.42,Away,2.10,3.20,2.95
predicted: 예측한 결과 (Home, Draw, Away)
pred_prob: 예측 확률
result: 실제 경기 결과
이 구조는 향후 모든 분석의 기준이 되며, 모델 성능을 정밀히 비교할 수 있는 기초가 된다. 이는 스포츠 예측모델과 실제 결과 비교 방법 완전정복의 첫 번째 실천 단계다.
3. 정답 여부 계산
정답 여부는 predicted와 result의 일치 여부로 판별하며, 이를 통해 전체 정확도(Accuracy)를 산출할 수 있다.
python
복사
편집
df['correct'] = df['predicted'] == df['result']
accuracy = df['correct'].mean()
print(f"전체 적중률: {accuracy*100:.2f}%")
이 수치는 전체 전략의 1차 성과 지표이며, 정답률이 높다고 해서 반드시 수익성이 높다고 보장되지는 않는다.
4. 예측 확률 신뢰도 분석
모델이 예측에 대해 얼마나 자신감을 가졌는지를 분석하면, 확률이 높은 예측이 실제로 얼마나 정확했는지 판단할 수 있다.
python
복사
편집
plt.hist(df['pred_prob'], bins=10)
plt.title("예측 확률 분포")
예: 예측 확률 0.7 이상인 경우의 적중률이 90%라면, 해당 구간은 신뢰도 높은 전략군으로 간주할 수 있다.
5. 혼돈 행렬 및 정밀도 분석
모델의 전반적인 성능은 Precision, Recall, F1 Score 등으로 정밀하게 측정할 수 있으며, Class별로 편향된 예측 여부도 확인 가능하다.
python
복사
편집
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(df['result'], df['predicted']))
print(classification_report(df['result'], df['predicted']))
이 분석은 스포츠 예측모델과 실제 결과 비교 방법 완전정복에서 ‘모델 리밸런싱’의 기초 단계로 활용된다.
6. ROI 계산
정확도는 높더라도 수익이 없다면 무의미하다. 배당 기반 ROI 계산은 실질 수익성을 판단하는 핵심이다.
python
복사
편집
def get_odds(r):
return r['home_odds'] if r['predicted']=='Home' else r['draw_odds'] if r['predicted']=='Draw' else r['away_odds']
df['used_odds'] = df.apply(get_odds, axis=1)
df['payout'] = df.apply(lambda r: r['used_odds'] * 1000 if r['correct'] else 0, axis=1)
roi = (df['payout'].sum() - len(df)*1000)/(len(df)*1000)
print(f"ROI: {roi*100:.2f}%")
7. 배당 구간별 성능 분석
배당 구간을 나눠 각각의 성과를 확인하면, 고배당 전략 또는 저위험 정배 전략 중 어느 쪽이 더 우수했는지 분석할 수 있다.
8. 리그/종목별 정확도 분석
경기 종목 또는 리그(EPL, 라리가, KBO 등)마다 경기 특성과 배당 구조가 다르기 때문에, 예측 전략이 특정 리그에서는 잘 맞고 다른 리그에서는 부정확할 수 있다.
이를 분석하면 다음과 같은 전략적 인사이트를 얻을 수 있다:
EPL에서는 정배 중심 전략의 ROI가 높음
K리그는 무승부 발생률이 높아 별도 대응 필요
NBA는 배당 편차가 작아 높은 확률 예측이 필수
분석 예시 코드:
python
복사
편집
df['league'] = df['home'].apply(lambda x: 'EPL' if 'Man City' in x else 'La Liga')
league_grp = df.groupby('league')['correct'].agg(['count','sum'])
league_grp['accuracy'] = league_grp['sum']/league_grp['count']*100
9. 시간대별 성과 비교
경기 시간이 결과에 영향을 미칠 수 있다. 예를 들어 유럽 축구는 현지 기준 저녁에 열리지만, 한국 시간 기준 새벽이라 베팅 성향이 달라질 수 있다.
분석 포인트:
낮 경기 vs 밤 경기 성과 차이
요일별 성과 비교 (주말 경기의 혼전성 등)
특정 시간대에 높은 ROI 기록 전략 식별
라벨링 예시:
python
복사
편집
df['time_of_day'] = df['date'].apply(lambda d: 'day' if int(d[-2:]) < 18 else 'night')
이 정보를 바탕으로 시간대에 따라 전략을 분리하거나, 고위험 구간을 차단하는 설정이 가능하다.
10. 누적 수익 시각화
단순 ROI 수치는 전체 수익 흐름을 설명하지 못한다. 누적 수익 그래프를 통해 예측 전략의 장기 안정성을 시각적으로 평가할 수 있다.
수익이 꾸준히 상승 → 전략 신뢰도 높음
급등락 반복 → 변동성 관리 필요
초기 손실 → 전략 초기 학습 부진 가능성
시각화 코드 예시:
python
복사
편집
df['cumulative_profit'] = df['payout'].cumsum() - 1000 * (df.index + 1)
df.plot(x='date', y='cumulative_profit', title='누적 수익 추이')
이는 투자 판단 및 전략 유지 여부를 결정하는 중요한 지표가 된다.
11. 예측 강도(p) vs 실제 정확도 비교
AI 예측 모델은 각 예측에 대해 ‘확신도(probability)’를 함께 제공한다. 이 예측 강도에 따라 실제 적중률이 일치하는지를 분석하면, 모델의 신뢰도 검증이 가능하다.
예시 구간 분류:
p > 0.9 → 확신 예측 → 실제 적중률이 높아야 정상
0.6 < p ≤ 0.7 → 중간 확신 → 전략 재학습 대상
p < 0.5 → 낮은 신뢰 예측 → 리스크 분리 또는 패스 처리
이러한 분석을 통해 베팅 필터 조건을 자동으로 구성할 수 있다.
12. 실패 패턴 분석
오답만 모아서 어떤 유형의 예측이 자주 틀렸는지를 분석하는 단계다. 예측 전략의 치명적인 약점을 조기에 발견하고 수정할 수 있다.
실전 인사이트 예:
Draw 예측은 전체 중 10%지만 실패의 40%를 차지함
고배당 예측은 대부분 실패 → 전략에서 제외 고려
특정 팀(예: Man Utd)의 예측 실패율이 높음 → 팀 기반 패널티 적용
코드 예시:
python
복사
편집
fails = df[~df['correct']]
print(fails.groupby('predicted').size())
이 결과는 다음 재학습 시 중요한 학습 데이터로 사용되며, 전략 수정의 핵심 근거가 된다.
13. Streamlit 자동 리포트 구성
Streamlit으로 작성된 리포트는 실시간으로 성과를 시각화하며, 내부 공유 또는 서비스용 대시보드로 활용 가능하다.
14. 피드백 루프 및 전략 재학습
예측 → 실제 결과 → 오답 분석 → 전략 조정 → 재학습 → 개선된 예측 생성
이 루프는 단순 분석이 아닌, 전략 최적화의 중심 구조다. 스포츠 예측모델과 실제 결과 비교 방법 완전정복을 반복 가능하게 만드는 본질적 설계다.
15~17단계 요약
Google Sheets 자동 연동: 예측, 결과, ROI, 정확도 등 통합 관리
자동 리포트 텍스트 생성: 자연어로 리포트 요약 작성
이메일/Slack 알림: 정기 리포트 자동 발송
이 기능은 시스템 운영자의 시간과 리소스를 절감하면서도 실시간 대응을 가능하게 해준다.
18. 모델 재학습 루틴
모델은 실시간 피드백을 바탕으로 지속적으로 개선되어야 한다. 오답 데이터를 강화 학습에 반영하고, 특정 클래스(예: Draw)에 대한 학습 비중을 조절한다.
19. 예측 출처별 성능 비교
수동 분석 vs AI vs 통계 기반 등 예측 출처별로 성능을 구분하면, 신뢰도 높은 출처 또는 전략을 선별해 전략 포트폴리오에 반영할 수 있다.
20. 전략 조정 및 개선 제안
분석을 통해 아래와 같은 전략 제안이 자동 생성될 수 있다:
확신도 높은 예측은 유지
Draw 예측 성능 낮을 경우, 별도 모델 분리
고배당 예측이 반복 실패 → 배당 상한선 조정
이처럼 전략 조정은 단순 수치 비교가 아니라, 성과 기반 전략 리빌딩을 유도한다.
✅ 최종 요약
스포츠 예측모델과 실제 결과 비교 방법 완전정복은 단순한 예측의 정확도 측정이 아닌, 전략의 실효성과 수익성까지 검증할 수 있는 20단계 피드백 루프를 제공한다.
예측-검증-재학습-전략 조정의 자동화 구조는 장기적인 전략 운영의 핵심이며, AI 모델뿐만 아니라 수동 분석에도 동일한 구조를 적용할 수 있다는 점에서 높은 실용성과 유연성을 자랑한다.
자주 묻는 질문 (FAQs)
Q1. 스포츠 예측 모델은 어떤 방식으로 작동하나요?
A1. 예측 모델은 과거 경기 데이터를 기반으로 AI, 통계, 수동 규칙 등의 방식으로 다음 경기의 결과를 예측합니다. 이 예측값은 확률(p)로 표현되며, 예측 강도 분석과 실제 결과 비교를 통해 성능을 검증합니다.
Q2. 예측 정확도가 높으면 반드시 수익이 나나요?
A2. 그렇지 않습니다. 예측 정확도(Accuracy)가 높아도, 선택한 배당 구간이나 베팅 전략에 따라 수익률(ROI)은 다르게 나타납니다. 예를 들어 정배(낮은 배당)의 경우 정확도는 높지만 ROI가 낮을 수 있습니다.
Q3. 수동 분석이나 커뮤니티 예측도 자동 분석이 가능한가요?
A3. 네. 예측 결과와 실제 결과를 같은 포맷(CSV 등)으로 정리하면 AI 예측뿐만 아니라 수동 분석, 커뮤니티 의견도 동일한 분석·리포트·ROI 비교가 가능합니다.
Q4. 예측 실패 시 전략 개선은 자동으로 되나요?
A4. 가능합니다. 오답 데이터를 수집하고, 일정한 규칙 또는 머신러닝 기반 피드백 루프를 통해 재학습하거나 전략 조정을 트리거로 설정할 수 있습니다. 예: 무승부 실패율이 높다면 별도 모델 적용을 제안할 수 있습니다.
Q5. Google Sheets, Streamlit, Slack 연동은 꼭 필요한가요?
A5. 필수는 아니지만, 자동화 효율성과 실시간 공유 기능을 극대화할 수 있습니다. 특히 비개발자 팀원과 협업할 때 Google Sheets는 매우 유용하며, Slack은 실시간 전략 알림에 효과적입니다.
Q6. ROI 계산 방식은 어떻게 되나요?
A6. 기본적으로 1회 베팅 1000원 기준으로, 수익률은 (총 수익 - 총 베팅금) / 총 베팅금 * 100%으로 계산됩니다. 예측이 맞았을 경우 해당 배당에 따라 수익이 누적됩니다.
Q7. 모델을 재학습하려면 어떤 데이터가 필요한가요?
A7. 예측값, 확률(p), 실제 결과, 배당, 리그 정보 등이 필요하며, 특히 오답 데이터를 포함해 어떤 조건에서 실패했는지를 포함해야 효과적인 재학습이 가능합니다.
Q8. 실패 패턴은 어떻게 분석하나요?
A8. 예측 실패 데이터를 필터링한 뒤, 예측된 방향, 배당 구간, 리그, 시간대 등 조건별로 분류해 실패가 집중된 영역을 식별합니다. 이를 통해 전략 리밸런싱 또는 리스크 회피 전략을 수립합니다.
#스포츠예측 #예측정확도 #ROI분석 #전략피드백 #피드백루프 #자동화리포트 #배당분석 #Streamlit리포트 #모델재학습 #예측전략분석
댓글목록
등록된 댓글이 없습니다.